AI is building data monopolies, leaving cryptocurrency behind.
The crypto industry, having spent a decade championing decentralization, now confronts a monumental challenge: the burgeoning dominance of artificial intelligence and, more specifically, the monopolistic control of data by companies like OpenAI, Google, and Anthropic. These AI firms are amassing vast datasets—trillions of tokens scraped from researchers, writers, and domain experts—and constructing permanent knowledge monopolies that dwarf the significance of decentralized finance (DeFi) protocols. Experts are warning that this concentration of data control represents a critical infrastructure battle, one that could ultimately determine the future of the entire blockchain landscape. A core contributor for OpenLedger, Ram Kumar, argues that the crypto industry’s current misallocation of attention – prioritizing yield farming and speculative token growth over fundamental infrastructure – is catastrophically failing to address this urgent issue.
The dynamic between crypto and AI is stark. DeFi demonstrated the potential to rebuild financial infrastructure transparently, with protocols competing on execution, composability, and user experience thanks to standardized assets like tokens and stablecoins. However, these financial rails are viewed as commoditized compared to the immense value and enduring power of centralized knowledge monopolies. AI data sets, unlike DeFi assets, are not portable. They’re locked inside proprietary training runs, costing upwards of $100 million and requiring months of intensive development. Once a foundational model reaches critical mass, replication becomes prohibitively expensive, creating a significant barrier to competition. Google, with its 20-year archive of search query data, Meta’s 15-year collection of social interaction data, and OpenAI’s partnerships with publishers—where content is perpetually licensed without onchain attribution—are establishing permanent moats, capitalizing on user interactions to amplify their models’ capabilities. This concentrates control over the information environment, a power that fundamentally challenges the core tenets of blockchain technology.
The urgency of this situation is underscored by the accelerated pace of AI development. Companies are already training models like GPT-5, Claude 4, and Gemini Ultra using massive datasets, often without compensating the creators whose work fuels these advancements. This lack of attention to data provenance represents a significant flaw in the current crypto strategy. Every training run that completes without onchain attribution reinforces centralized control and makes it harder for new entrants to gain ground. Once these models reach sufficient capability, they exhibit self-reinforcing dynamics: users generate data through interactions, which trains the next iteration, and the next iteration attracts more users, accelerating the flywheel. The potential for competition diminishes dramatically as competitors lack both the initial corpus and the ongoing data stream. Ram Kumar estimates that the crypto industry has perhaps only two years before this window of opportunity closes permanently, predicting that data set monopolies will become entrenched facts of nature, resistant to disruption by even the most advanced decentralized infrastructure.
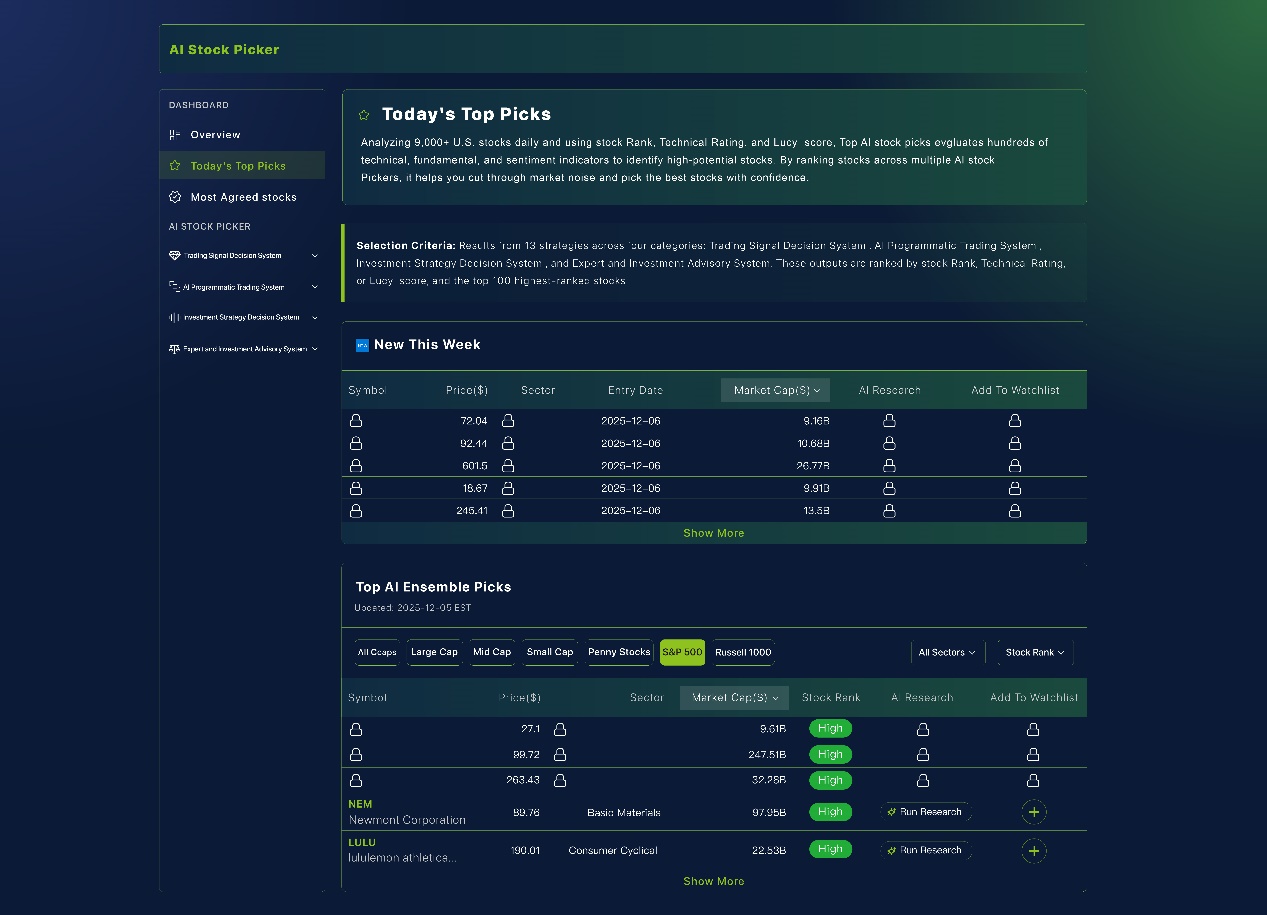
Instead of continuing to invest in more decentralized exchanges (DEXs) or focusing on token velocity, the crypto industry needs to prioritize the development of data set registries—systems where contributions would be cryptographically signed before training begins. These registries would incorporate attribution protocols that meticulously log which data sets influenced specific model outputs, alongside micropayment rails designed to automatically distribute revenue proportionally among the original creators. Furthermore, robust reputation systems could rank data set quality based on measured model performance, rather than relying solely on subjective metrics. The technological requirements for such an infrastructure are surprisingly straightforward: cryptographic hashes, contributor wallet addresses, standardized licensing terms, and usage logs. Training runs would record the data used and when it was used, routing payment requests to registered contributors. This approach avoids the need for radical new consensus mechanisms or experimental cryptography, opting instead for builders who prioritize preventing monopolies over pursuing liquidity rewards.
Ultimately, the crypto industry stands at a critical juncture. It can either continue down its current path—investing in speculative assets while AI companies solidify their control over information—or it can proactively build the infrastructure necessary to prevent these monopolies from ever forming. Failing to do so would effectively constitute crypto’s obituary, painting a picture of a movement that championed decentralization but was ultimately unable to address the most powerful technological trend of the 21st century. The industry’s founding thesis revolved around preventing centralized control over valuable networks, but if AI companies monopolize intelligence, those victories become meaningless. Indeed, the future of crypto depends on its ability to safeguard the very information environment that underpins its existence. A proactive shift towards data set attribution infrastructure represents the only viable strategy to ensure crypto’s relevance and longevity in a world increasingly dominated by centralized AI.
The industry needs to build this infrastructure immediately. The potential rewards—a truly decentralized and equitable information ecosystem—far outweigh the challenges. This is not merely about protecting blockchain; it’s about preserving the freedom of expression, the integrity of knowledge, and the future of innovation. The choice is clear. Investing in data set attribution is not crypto’s obituary; it’s its salvation.